Somebody once asked me for reccomendations on MBA programs based on rank and tuition. I didn’t have any information on hand, but knew how toget it. Webscraping.
Webscraping is an immensly useful tool for gathering data from webpages, when it isn’t hosted on an API or stored in a file somewhere. R’s best tool for webscraping is Rvest.
So I decided to scrape information on the US News website for university rankings, which has at least 20 pages of MBA probrams available. To copy and paste that much data into a spreadsheet would be annoying and quite an eye strain.
library(tidyverse)
library(stringr)
library(rvest)Of course, before writing a scraper, one needs to code it according to the page layout.
I find that:
- There are 19 pages of information I need.
- Everything is directly available on those pages, no need to iterate over additional, internal links.
- Xpath selectors perform better than CSS selectors in this particular example.
I will use lapply to run through all 19 pages, with the sprintf function to help paste the new page number in each time, for each new iteration.
## 19 pages of MBA programs on US News website.
pages <- 1:19
get_usnews_mbas <- function(x) {
website1 <- 'https://www.usnews.com/best-graduate-schools/top-business-schools/mba-rankings/page+%s'
url <- sprintf(website1, x, collapse = "")
website <- read_html(url)
base_url <- 'http://www.usnews.com'
University <- website %>%
html_nodes('.school-name') %>%
html_text()
Location <- website %>%
html_nodes(xpath = '//*[@id="article"]/table/tbody/tr/td[2]/p') %>%
html_text()
Link <- website %>%
html_nodes(xpath = '//*[@id="article"]/table/tbody/tr/td[2]/a') %>%
html_attr("href") %>%
str_trim(side = "both")
Tuition <- website %>%
html_nodes(xpath = '//*[@id="article"]/table/tbody/tr/td[3]') %>%
str_replace_all("\n", "") %>%
str_replace_all(",", "") %>%
str_extract("\\d+") %>%
as.integer()
##Combine vectors into data frame
data_frame(University,
Location,
Tuition,
Link)
}Apply the function, get the data!
USNEWS_MBAS <- do.call(rbind, lapply(pages, get_usnews_mbas))Rvest made this feel almost like magic - Pulling it into R without having to do any manual clicking, copying, and pasting. As I said, web scraping is very powerful!
Clean the Data
##Split location into City and State.
USNEWS_MBAS <- USNEWS_MBAS %>%
separate(Location, c("City", "State"), sep = ",")
##Create column for rankings...
USNEWS_MBAS <- USNEWS_MBAS %>%
mutate(Rank = 1: n())
##The URL's didnt scrape 100% correctly. But it is easy to paste the base URL onto each branch.
base_url <- 'www.usnews.com'
USNEWS_MBAS <- USNEWS_MBAS %>%
mutate(base_url = base_url) %>%
unite(Links, base_url, Link, sep = "")That’s enough data cleaning, but adding a variable to segment or classify the schools into brackets of ten could be useful when visualizing them in terms of rank and tuition cost later.
USNEWS_MBAS <- USNEWS_MBAS %>%
mutate(Tier = cut(Rank, breaks = seq(0, 400, by = 10))) %>%
mutate(Tier = str_replace(Tier, ",", "-")) %>%
mutate(Tier = str_replace_all(Tier, "[^0-9-]", ""))
##Convert intervals into factors
USNEWS_MBAS$Tier <- factor(USNEWS_MBAS$Tier, levels = c("0-10", "10-20", "20-30", "30-40", "40-50", "50-60", "60-70", "70-80", "80-90", "90-100", "Out of Top 100"))
USNEWS_MBAS %>%
select(University, City, State, Tuition, Rank, Tier, Links)## # A tibble: 475 x 7
## University City State Tuition Rank Tier Links
## <chr> <chr> <chr> <int> <int> <fct> <chr>
## 1 Harvard Universi… Boston " MA" 72000 1 0-10 www.usnews.com/best…
## 2 University of Ch… Chica… " IL" 69200 2 0-10 www.usnews.com/best…
## 3 University of Pe… Phila… " PA" 70200 3 0-10 www.usnews.com/best…
## 4 Stanford Univers… Stanf… " CA" 68868 4 0-10 www.usnews.com/best…
## 5 Massachusetts In… Cambr… " MA" 71000 5 0-10 www.usnews.com/best…
## 6 Northwestern Uni… Evans… " IL" 68955 6 0-10 www.usnews.com/best…
## 7 University of Ca… Berke… " CA" 58794 7 0-10 www.usnews.com/best…
## 8 University of Mi… Ann A… " MI" 62300 8 0-10 www.usnews.com/best…
## 9 Columbia Univers… New Y… " NY" 71544 9 0-10 www.usnews.com/best…
## 10 Dartmouth Colleg… Hanov… " NH" 68910 10 0-10 www.usnews.com/best…
## # ... with 465 more rowsLet’s filter the schools and grab only the top 100.
USNEWS_MBAS %>%
filter(Rank <= 100) %>%
ggplot(aes(x = Rank, y = Tuition, color = Tier)) + geom_point() +
ggtitle("American MBA Programs", subtitle = "By Rank and Tuition")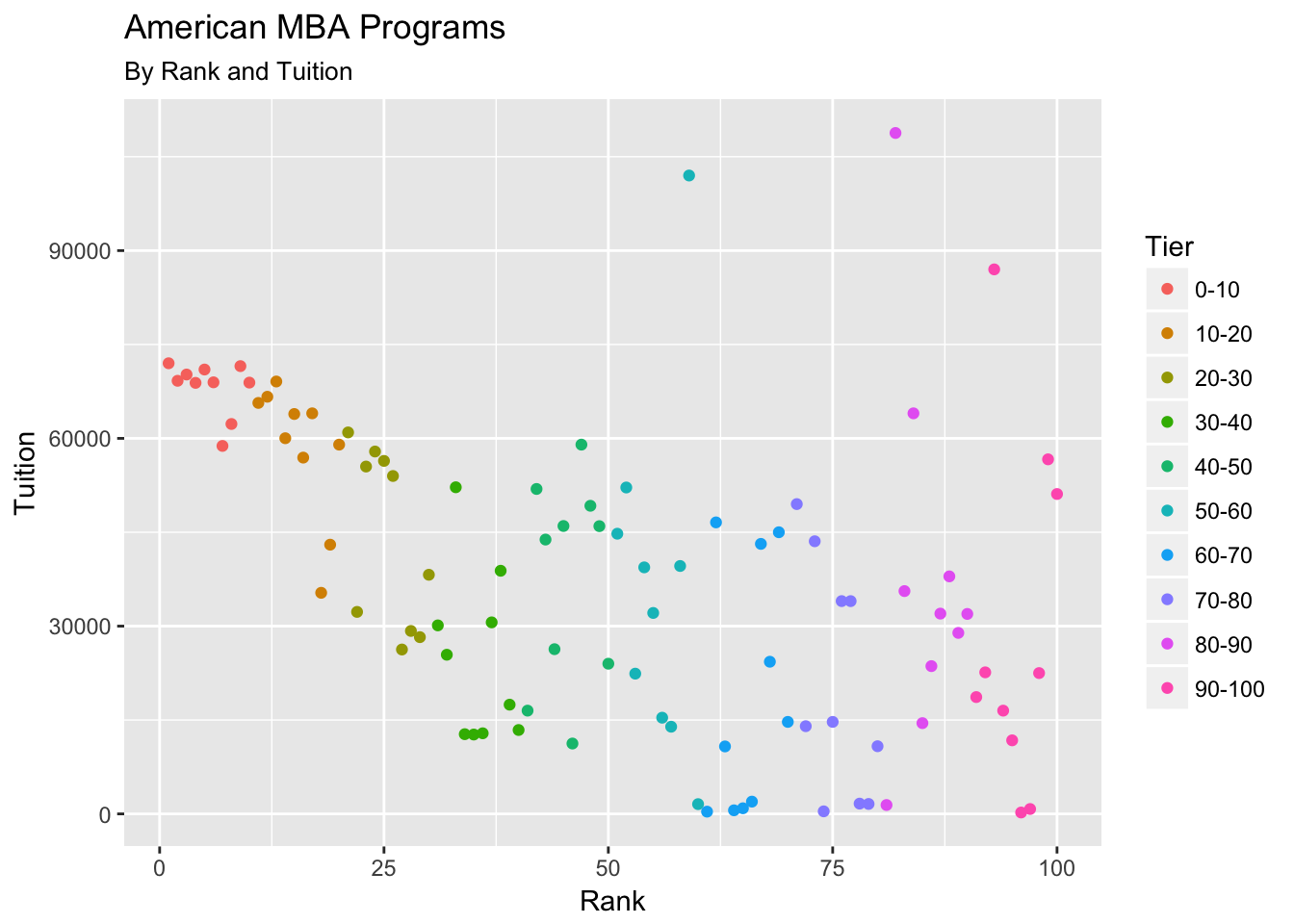
Some top 20-30 schools look to be a good deal in terms of high rank and (relatively) lower tuition. But if one goes for schools ranked in the 30-40 range, then the tuition gets even lower.
A more detailed look
USNEWS_MBAS %>%
select(University, Rank, Tuition, Tier) %>%
arrange(Rank, Tuition) %>%
group_by(Tier) %>%
top_n(-3, Tuition) %>%
ggplot(aes(x = reorder(University, -Rank), y = Tuition, fill = Tier)) +
geom_bar(stat = "identity") +
coord_flip() +
ggtitle("Three 'Cheapest' Schools per Tier", subtitle = "MBA Programs") +
xlab("University")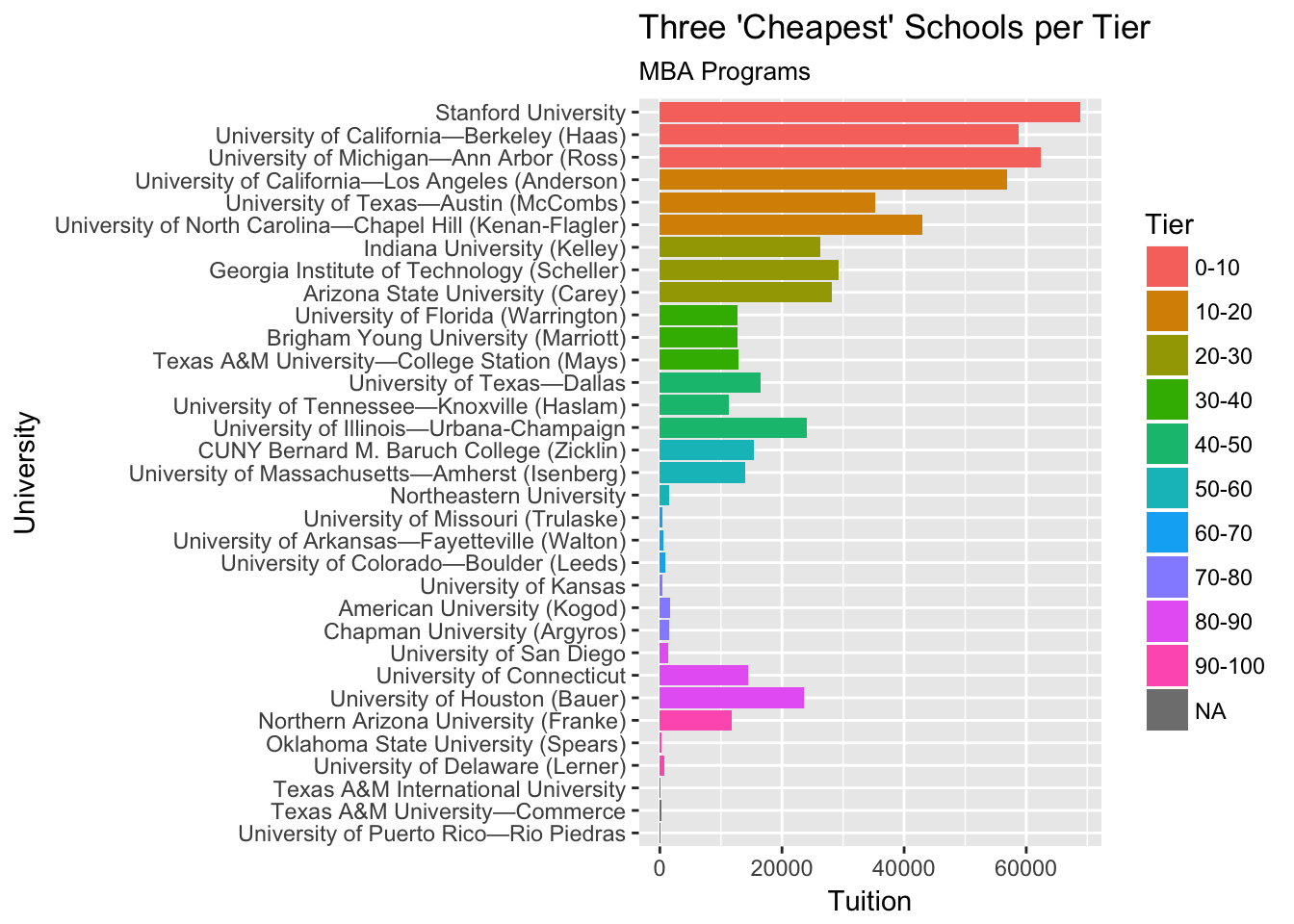
Up above, I selected 3 institutions from each “Tier” of rankings with the lowest tuition and plotted them. Some universities have suspiciously low tuition, which is likely due to documentation error on the US News website.
Some Observations
- MBA programs are very expensive for any institution ranked from 1-30.
- Programs become affordable from ranks 30-50 and onward
- Anything that appears especially low is probably an inconsistency in US News’ tuition data.
- It’d be better to compare school rankings across a certain program instead of comprehensively
Migrated from my original Wordpress blog